WordPress-Performance: MySQL vs. Apache
Gestern Abend durfte ich im Rahmen eines Kundenprojekts einmal mehr Erfahrungen im Umgang mit »High traffic« auf einem WordPress-Blog machen. Es handelt sich dabei um einen Blog der im Normalfall täglich zwischen 8.000 und 20.000 Unique Visitors hat und mit eingen Plugins (üblicher Umfang) ausgestattet ist.
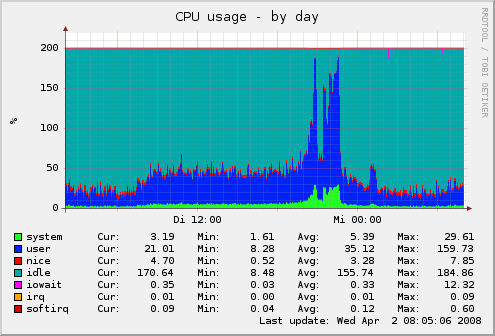
Gegen 20 Uhr hat ein Ausnahmesituation dann dazu geführt, dass innerhalb kürzester Zeit die Besucherzahlen stark angestiegen und für ca. 1-2 Stunden sehr hoch geblieben sind. Interessant war dabei die Entwicklung der Serverlast auf unterschiedlichen Ebenen. Das Projekt läuft auf diesem Server und unter meiner Betreuung seit ca. 4 Monaten. Die Konfiguration des Servers wurde durch die Erfahrungswerte der letzte Wochen und Monate immer wieder angepasst und läuft seit einiger Zeit auch bei kleineren Lastspitzen absolut Problemfrei. Der gestrige Ansturm jedoch hat dazu geführt, dass die Hardware an seine Grenzen geführt wurde. Die Unix-Load war zu Spitzenzeiten bei Knapp unter 100 anzufinden. Im normalen Betrieb steigt sie selten über 1.
Die Analyse der Situation während des Ansturms und danach hat einige überraschende Aspekte hervorgebracht. Zum einen war entgegen meinen ersten Vermutungen der Datenbank-Server (MySQL) in keinster Weise schuld an der Auslastung. Klar stieg die Anzahl der Queries (Abfragen) in die Höhe, jedoch wurden nahezu alle vom großzügig angelegten Query Cache abgefangen, der sich komplett aus dem Arbeitsspeicher bedient und dadurch auch dafür gesorgt hat, dass der Webserver selbst bei recht hoher Systemlast noch zügig antworten konnte.
Die Auslastung des Arbeitsspeichers (insgesamt 4 GB) war während der ganzen aktion absolut im grünen Bereich. Grund dafür ist wohl vor allem die Tatsache, dass es sich fast ausschließlich um Lesezugriffe auf den DB-Server handelte und vorwiegend ein Beitrag aufgerufen wurde, der probemlos aus dem Cache geliefert werden konnte. Das tatsächliche Problem war zu Spitzenzeiten dann der Webserver (Apache 2.x) der bis zu 90 Requests/Sekunde handeln musste. Wie schon ander oben erwähnten geringen Memory-Auslastung zu erkennen war auch gar nicht der sonst oft erwähnte hohe Memoryfootprint des Indianers das Problem sondern eher die CPU-Last die dadurch entstand. Aus diesem Grund hat auch die kurzfristige Zuschaltung von WP-Supercache erwartungsgemäß keinen Erfolg gebracht.
Das eigentliche Problem beim hohen Resourcenverbrauch des Apache-Webservers sind dabei gar nicht unbedingt die blanken Userzugriffe auf dynamische Seiten, sondern eher die statischen Dateien die beim Aufbau der Seiten geladen werden. Dazu gehören z.B. Bilder des Layouts, Icons, kleine Javascript-Dateien etc. pp. Für jede dieser Dateien wird eine eigene Verbindung aufgebaut und belegt damit grundsätzlich erstmal den Verbrauch, den eine Verbindung braucht – egal ob sie einen Datenbankrequest zur Folge hat oder nicht. Pro Aufruf einer Seite entstehen so schnell mehr als 20 oder 30 Anfragen an den Webserver, Während der Spitzenzeit war das gut über den Statusmonitor des Webservers zu erkennen. EIn nicht unerheblicher teil der offenen Verbindungen kam durch Social-Bookmarking-Icons und ähnliches zu Stande. Mein Vorschlag an den Kunden wird daher sein den größten Teil der statischen Dateien – soweit möglich – auf einen zweiten Webserver (z.B. Lighttpd “Lighty”) auszulagern, der mit wesentlich weniger Resourcen klar kommt und auch für die Auslieferung dieser statischen Dateien optimiert wird. Das sollte die Ladegeschwindigkeit der Seiten noch einmal deutlich erhöhen und vor allem den Server bei Zugriffsspitzen deutlich entlasten.
Trotz allem wurde der gestrige Ansturm vom Server gut abgearbeitet und bis auf wenige Momente war die Seite problemlos erreichbar.
Lighty ist schon wieder out, nginx ist der neue Liebling, zumindest für Rails.
Zusätzlich würd ich empfehlen die JS-Sachen zu bündeln in nur eine Datei, genauso das CSS.
Bei den kleineren Grafiken wären sprites eine Möglichkeit.
wie kann ich sonst einen high-traffic-wordpressblog monitoren? wie kann ich (womit) den server beobachen? haben sie weitere tipps, an welchen schrauben man drehen kann? kann man folgende aussage so behaupten:“ in spitzenzeiten ist wordpress einer „statischen website“ vorzuziehen?“
viele grüße
Was sind spitzenzeiten? Zeiten zu denen besonders viele Zugriffe passieren? Dann nein.
Was soll beim Monitoring des High-Traffic-Blogs beobachtbar sein? Die Besucher? Die Serverlast?
Die Fragen sind allesamt so nicht zu beantworten ohne die Details zu kennen. Wenn Sie einen Server selbst betreiben bzw. administrieren, dann sollten entsprechende Systemmonitoringtools (abhängig vom Betriebssystem) bekannt sein. Wenn sie einen Managed Server oder Webhosting-Account nutzen, dann sind die Monitoringmöglichkeiten ohnehin eher begrenzt bzw. ist in der Regel kein Monitoring der Systemfitness möglich.
Monitoring heißt für mich dass per mail oder sms eine Nachricht bekomme wenn die Zugriffszeit auf eine Seite zu lang wird oder gar keiner mehr durchkommt.
Ein guter Cache wird (immer) statische Seiten ausliefern, da sind dann mindestens 5000 oder mehr requests/sec möglich.
Zur Optimierung:
* So wenig SQL-Queries wie möglich
* Intelligente Queries (da hilft oft nur Erfahrung)
* So wenig Festplatten Zugriffe wie möglich
* YSlow installieren, verstehen und nutzen
Die ersten Optimierungen hat man immer schnell gefunden und können manchmal schon ausreichend sein, aber jeder Software ist anders.